讲明白编码/解码
程序中的“编码”和“解码”,“字符”和“文本”,都是老生常谈的问题,理解清楚这些概念和原理,当遇到相关问题的时候便能快速找出解决方案,节约时间。本文在这里尽可能简单的一次性说明白这些概念和其内中的原理。
字节
在目前主流的操作系统里,八个比特位(bit)就是一个基本单位,也就是字节(byte)。
字符
编码
始于 ASCII
把比特对应到字符的方法,就是编码(encoding)。对于英文字符和常用的标点符号来讲,用一个字节表示一个字符完全够用,因此英文中最基础的 ASCII 编码集就是采用这种编码方式。由于计算机兴起于美国,最早期也就只有这一个编码集。
目前的大部分编码方式(下面会讨论到),在 0-127 的范围里,字节值和字符的对应关系是基本相同的。除了个别字符外,编码的基本方式都和 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)兼容,如下图所示:
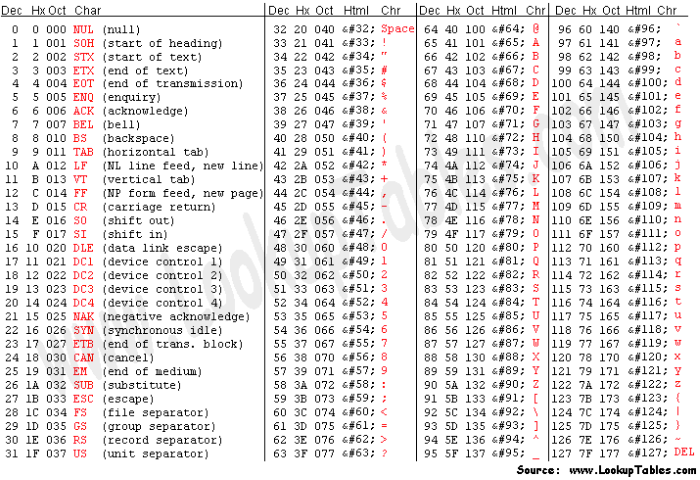
注意,头 32 个字符和最后一个字符是控制字符,其中大部分现在已经很少有人使用了,但还有一些我们今天仍然会在不同的场合遇到,如马上就会讨论的 LF 和 CR。
其他编码集的诞生
ASCII 是美国标准,里面只有基本的拉丁字母,对其他国家来讲可能就不合适。比如对欧洲国家来说,ASCII 既没有带变音符的拉丁字母(如 é 和 ä ),也不支持像希腊字母(如 α、β、γ)、西里尔字母(如 Пушкин)这样的其他欧洲文字,使用起来很不方便。很多其他编码方式使用了 128-255 的字节值范围作为扩展,总共最多是 256 个字符,一次允许一套方式生效,称之为一个代码页(code page)。这种做法,只能适用于文字相近、且字符数不多的国家。比如,下图表示的 ISO-8859-1(也称作 Latin-1)和后面的 Windows 扩展代码页 1252(下图中绿框部分为 Windows 的扩展),就只能适用于西欧国家。
最早的中文字符集标准是 1980 年的国标 GB2312,其中收录了 6763 个常用汉字和 682 个其他符号。至于我们平时用到的编码 GB2312,它更准确的名字其实是 EUC-CN,是一种与 ASCII 兼容的编码方式。它用单字节表示 ASCII 字符而用双字节表示 GB2312 中的字符;由于 GB2312 中本身也含有 ASCII 中包含的字符,在使用中逐渐就形成了“半角”和“全角”的区别。
国标字符集后面又有扩展,这个扩展后的字符集就是 GBK,是中文版 Windows 使用的标准编码方式。GB2312 和 GBK 所占用的编码位置可以参看下面的图(由 John M. Długosz 为 Wikipedia 绘制):
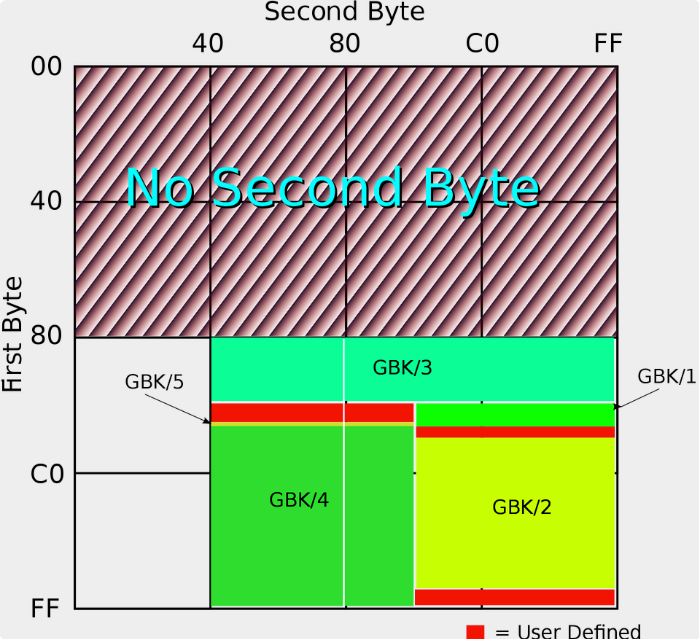
图中 GBK/1 和 GBK/2 为 GB2312 中已经定义的区域,其他的则是 GBK 后面添加的字符,总共定义了两万多个编码点,支持了绝大部分现代汉语中还在使用的字。
统一于 UNICODE
UNICODE(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字进行了整理、编码。Unicode 使计算机呈现和处理文字变得简单。
UNICODE 统一了所有文字的编码,对于 ASCII 而言,只需要在前面补 0 就可以在 UNICODE 中表示了。Unicode 自发明伊始,就是为了统一编码问题,但它的最早编码方式,UCS-2,存在两个重大问题:
- 和 ASCII 不兼容,不能在现有软件和文件系统中直接使用
- 在储存 ASCII 为主的字符时,存在一字节变两字节的空间浪费
Unicode 至今仍在不断增修,每个新版本都加入更多新的字符。目前 Unicode 最新的版本为 2020 年 3 月 10 日公布的 13.0.0,已经收录超过 14 万个字符。
现在的 Unicode 字符分为 17 组编排,每组为一个平面(Plane),而每个平面拥有 65536(即 2 的 16 次方)个码值(Code Point)。然而,目前 Unicode 只用了少数平面,我们用到的绝大多数字符都属于第 0 号平面,即 BMP 平面。除了 BMP 平面之外,其它的平面都被称为补充平面。
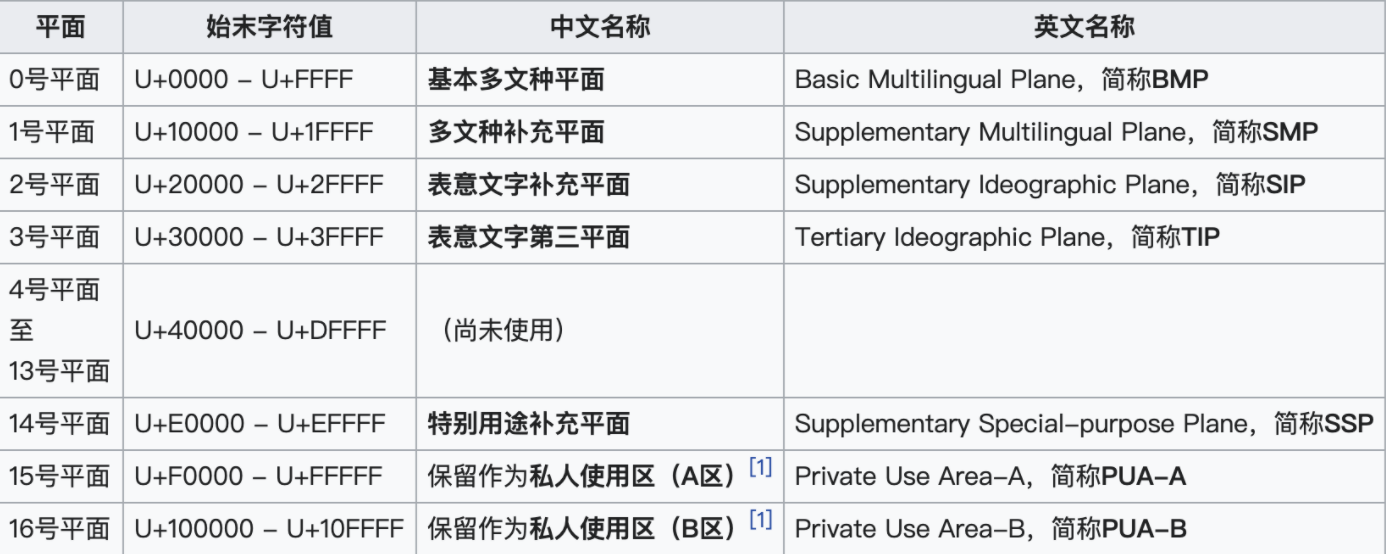
Unicode 标准也在不断发展和完善。目前,使用 4 个字节的编码表示一个字符,就可以表示出全世界所有的字符。
UNICODE 中最重要编码方式 UTF-8
UTF-8,它的全称是 8-bit Unicode Transformation Format,8 比特的 Unicode 转换格式。Ken Thompson 在 1992 年和 Rob Pike(罗勃 · 派克)一起发明了 UTF-8,解决了上面提到的 Unicode 的两个问题。到了今天,UTF-8 已经成了互联网和 Unix 世界里文本文件(含 HTML 和 XHTML)的主流编码方式。但是,Windows 下的文本文件,由于历史原因,可能还大量使用着传统的编码方式(很错误地被叫做 ANSI);对于中文 Windows,这个传统编码就是 GBK 了。
字形
Unicode 设计时的一个决定,目前看起来有点短视,那就是对中日韩文字中使用到的汉字进行了“统一”。如果字源相同,它们在 Unicode 中就只占据一个编码点。于是,一个字符可能就有多个字形。

跟中文字符集中“半角”和“全角”的概念有点像,Unicode 中也有字宽的概念。和简单的半角与全角的区别不同,Unicode 里除了窄字符和宽字符,还有模糊宽度(ambiguous width)字符。这些字符的宽度根据上下文而定:在东亚文字里一般是宽字符,而在西方文字里一般是窄字符。最常用的模糊宽度字符有(“U+”后面跟十六进制数值是用来表示 Unicode 字符所占编码点数值的通常方法):
- U+00B0:「°」
- U+00B7:「·」
- U+00D7:「×」
- U+00F7:「÷」
- U+2014:「—」
- U+2018:「‘」
- U+2019:「’」
- U+201C:「“」
- U+201D:「”」
- U+2103:「℃」
对于某一特定字体,它们的宽度当然就是确定的;尤其使用变宽字体(大部分英文字体,不同字符宽度不同)时。对于使用等宽字体(程序员一般使用的字体)的文本编辑器,到底是把这些字符显示成跟 ASCII 字符一样的“单”宽度,还是显示成跟汉字一样的“双”宽度,就是一个需要考虑的问题了。
这个模糊宽度,在我们日常生活中还是造成了一点麻烦的。非常常见的一个排版错误,就是由于使用的软件(在中文 Windows 下的)的字体选择规则,西文中的 「’」误用了中文字体展示,导致这个符号展示出来的字间距过宽。一个相反的麻烦,是中文中写「·」希望两侧留空很足,但在另外一些环境下,永远优先选择西文的字体(如大部分的手机操作系统),导致需要手工两侧加空格才能有比较理想的排版效果。
文本
从二元论的角度看,计算机文件可以分为文本文件(text file)和二进制文件(binary file),但这个分法并没有对文本做出清晰的界定。从实用的角度,我们大致可以这么区分:
- 文本文件里存放的是用行结束符(EOL,即 End of Line)隔开的文本行,二进制文件里则没有这样的明确分隔符
- 文本文件可以通过简单、直接的算法转换为人眼能够识别的文字,而二进制文件里含有不能简单转化为文字的信息
现代的操作系统基本上在文件系统层面完全不关心文件的类型和里面的内容了。因为操作系统不对文件类型进行限定,会更加灵活。
行
一个文本文件由多行构成,每一行都以一个行结束符(EOL)结束。根据传统习惯,这个 EOL 在存盘时使用的字符是 LF,编码值是 10(U+000A)。
这只是 Unix 格式。常用的还有 DOS 格式(也包括了 Windows),以及老的 Mac 格式。
在 DOS 格式里,行尾就不只使用 LF 这一个字符了,在 LF 前面会多一个 CR,编码值为 13(U+000D)。这个用法的来源是以前的打字机,CR 表示机架归位(carriage return),LF 表示换行(line feed)。在使用 CR LF 作为行结束符的系统里,CR 只负责光标回到第一列,而 LF 负责光标向下一行。
老的 Mac 则使用单个 CR 字符作为行结束符,但苹果从 Mac OS X(2001 年)开始就使用了 Unix 风格的行结束符。所以,目前我们遇到的文本文件,应当都使用 LF 或 CR LF 作为行结束符了。
实例分析
编码集之间的转换
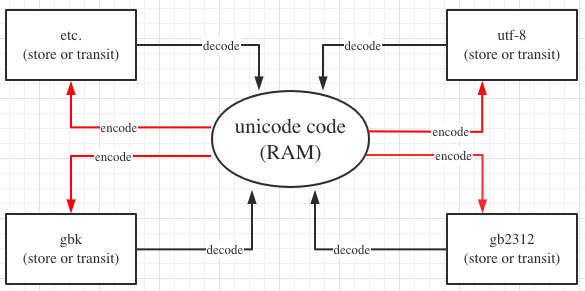
从上图我们可以看出,可以把 UNICODE 编码作为一种中间编码来看待,其他编码可以通过 UNICODE 进行相互转化。当一种编码转成 UNICODE 编码的过程我们叫 decode,当把 UNICODE 转成一种特定的编码的过程我们叫 encode。由于 UNICODE 是定长的,因此大多数程序编码一般会使用 UNICODE 作为程序的默认编码形式(python2.7 除外)。
但是上图的转换取决于“字符集”是否支持“所转换的文字”。比如俄语和日语既可以使用 GBK 表示也可以使用 windows-1251(俄语常用的字符集)。因此俄语和日语可以通过上图进行转换。但是土耳其语则不能用 GBK表示。
俄语在通过 gbk,gb2312,windows-1251 进行编码
1 | lang = "Привет" |
土耳其语 gbk 进行编码
1 | land = "Avrupa-lı-laş" |
编码集在数据传输的作用
UNICODE 相当于规定了字符对应的码值,这个码值必须编码成字节的形式去传输和存储。最常见的编码方式是 UTF-8,另外还有 UTF-16,UTF-32 等。UTF-8 之所以能够流行起来,是因为其编码比较巧妙,采用的是变长的方法。也就是一个 UNICODE 字符,在使用 UTF-8 编码表示时占用 1 到 4 个字节不等。最重要的是 UNICODE 兼容 ASCII 编码,在表示纯英文时,并不会占用更多存储空间。而汉字呢,在 UTF-8 中,通常是用三个字节来表示。
1 | lang = "你好" |
文件编码的存储和程序编码的存储
有时候,我们对于“程序文件编码的存储”和“所写程序中的编码”有时候会混淆。当然现在IDE一般存储文件都用 utf-8 的编码,基本屏蔽了这个问题。但是在早些年,编程文件所使用的编码也会跟着系统编码走的,尤其当我们使用非英文的文字的时候,保存文件后再打开(使用其他编码打开)有可能会出现乱码。
比如 python 文件我们一般会在头部先写上 # -*- coding: utf-8 -*- 表示当前文件的存储编码是 utf-8,这个和写的程序无关。而 sys.setdefaultencoding('utf-8') 表示我们声明的变量都是用 utf-8 的编码存储和传输的而不关心系统的默认编码。
json.dumps的参数: ensure_ascii=False
json_dumps(dict)时,如果dict包含有汉字,一定加上 ensure_ascii=False。否则按照参数的默认值 True,意思是保证dumps之后的结果里所有的字符都能够被 ASCII 表示,汉字在 ASCII 的字符集里面,因此经过dumps以后的str里,汉字会变成对应的 UNICODE。
虽然在Python3 里面汉字在内存里就是 UNICODE 表示,这里 str 里面的 UNICODE 经过 loads 也能还原成汉字,看起来似乎没什么问题。
但这样的操作只适合 python,你能这么做是因为 python 认识 UNICODE,python在执行 json.loads 的时候知道 UNICODE 是用来表示汉字而不是真的几个 char 拼接在一起,所以会对“\u”开头的这种字符串做转义理解。
不过以上转义理解是 python 中 json.dumps 和 loads 自己所遵守的规则,并不是通用的规则。
如果你脱离了 python,比如把这串字符串以一定的方式送出去(写入文件或者通过网络发送),给另外的应用程序(比如记事本)处理,这个应用看到 “\u45ef” 就会老老实实的认为这是1个包含了6个 char 的字符串,绝不会跟1个汉字扯上联系。
1 | a = {"hello" : "好"} |
为什么输入数字或者英语 encode 返回的是它本身,但是中文日文什么的就会返还一些字母 + 数字
先介绍两个函数和进制表示法:
ord()得到的是 Unicode code point,范围是0x0000到0xFFFF,称为UCS-2编码。utf-8编码在这里是三字节。hex()hex 可以将二进制转变为十六进制。\u表示 UNICODE 编码,\x表示16进制数。- 十进制
110119在二进制表示为0b11010111000100111,在十六进制表示为0x1ae27,在八进制表示为0o327047。
b'abc' 这种形式就是字节串,而不是二进制串。如何得到一个字符的二进制表示形式呢?可以通过 ord() 和 hex() 得到二进制和十六进制表示。
1 | >>> ord('中') |
由于英文字母在 utf-8,gbk 这些编码中占用一个字节,因此这些编码集兼容 ASCII,也就是说 ASCII 是这些编码集的子集。而像中文日文需要多余一个字节表示。
1 | # 中文 encode |
也就是说,对于 ASCII 编码,通常很多编码都是相同的。但是涉及到中文、日文、emoji等,往往需要多个字节来表示,这个时候取决于具体编码标准会有不同,比如 GBK、GB2312、UTF-8、UTF-16等等。
参考文档
[1] ASCII码与汉字的编码有什么区别: https://zhidao.baidu.com/question/1992697642196307547.html
[2] 【Python】json.dumps的参数:ensure_ascii=False: https://zhuanlan.zhihu.com/p/37504880
[3] 关于json.dumps中的ensure_ascii: https://blog.csdn.net/djskl/article/details/25225885
[4] 彻底搞懂编码ASCII、Unicode、GBK 和 UTF8 、UTF-16、UTF-32编码方式(非常经典): https://blog.csdn.net/lc11535/article/details/100013653
[5] 字符编码笔记:ASCII,Unicode 和 UTF-8: https://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
[6] python encode ascii_python中,为何输入print(“a”.encode(“ASCii”))出来显示的是b‘a’?: https://blog.csdn.net/weixin_39628063/article/details/110696348
[7] 一文彻底搞懂Unicode编码问题: https://zhuanlan.zhihu.com/p/370601172
[8] Unicode 是不是只有两个字节,为什么能表示超过 65536 个字符: http://www.wjhsh.net/crazylqy-p-10482097.html
[9] python中的编码和解码及\x和\u问题: http://www.45fan.com/article.php?aid=1CZUme3YrG1N9A2B